The structural architecture of web content has undergone a fundamental paradigm shift. In traditional search engine optimization (SEO), internal links were treated primarily as crawling paths for search engine spiders (like Googlebot) and a mechanism to distribute PageRank.
While these functions remain critical, the rise of Generative Engine Optimization (GEO) and Answer Engine Optimization (AEO) has elevated internal linking to a new role: it is the physical training ground and semantic blueprint of your domain’s Knowledge Graph.
Today, search engines like Google (via AI Overviews), Perplexity AI, and ChatGPT Search do not merely catalog individual, isolated documents. Instead, they use Retrieval-Augmented Generation (RAG) and dense vector retrievers to synthesize answers.
They analyze the relationship between concepts, entities, and pages. If your site architecture fails to communicate how your pages interrelate, your content risks becoming invisible to both traditional indexes and modern AI models.
This blueprint provides a comprehensive, step-by-step technical guide to designing, implementing, and automating an internal linking architecture optimized for both human users and AI retrievers.
What is Internal Linking?
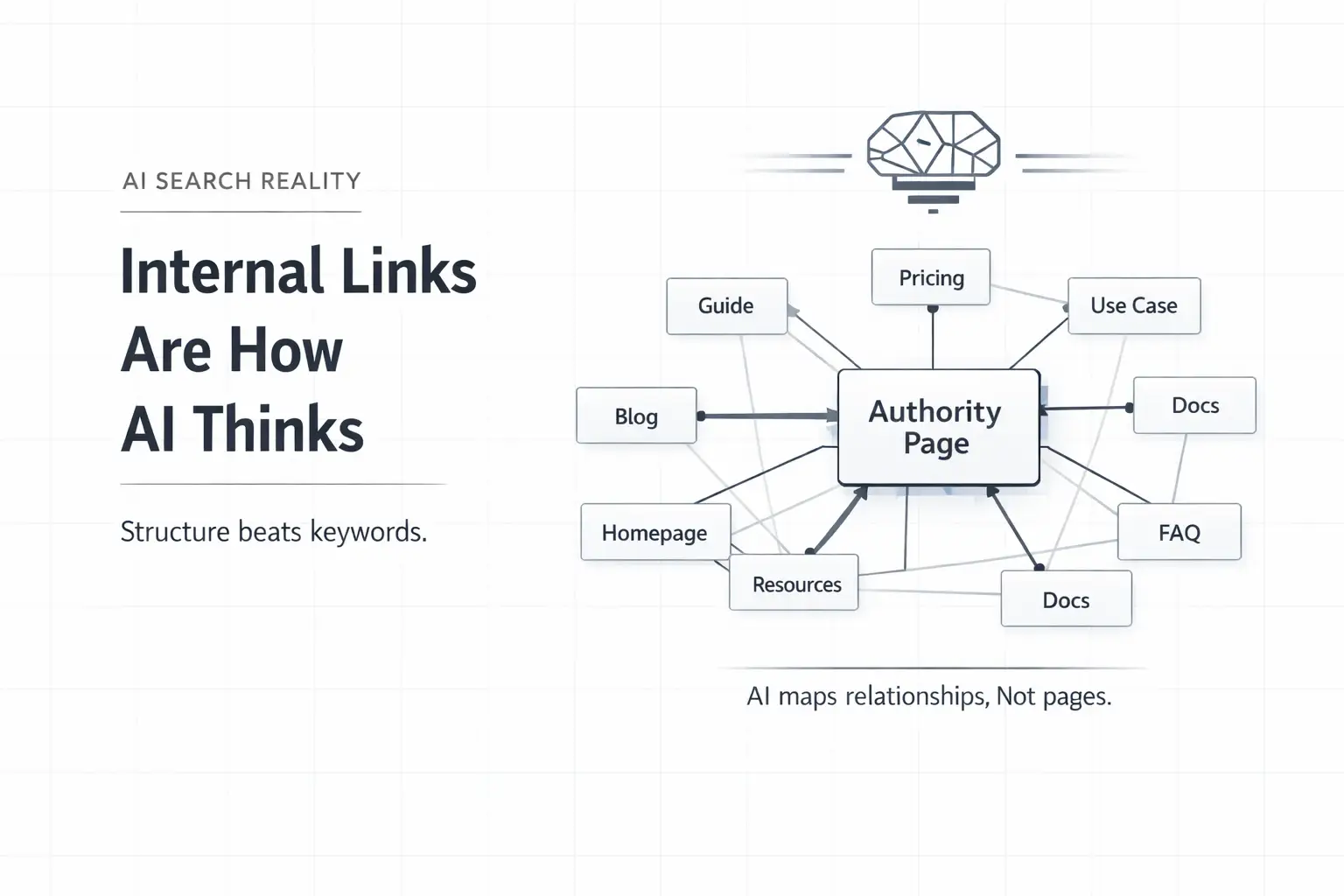
At its simplest level, internal linking is the practice of connecting one page of your website to another using a hyperlink. But for both human readers and AI search engines, it is much more than just navigation—it is the nervous system of your website.
When you link Page A to Page B, you are sending a specific signal: “This content is related, and it is important.”
For humans, these links provide a path to deeper knowledge, keeping them on your site longer. For AI search engines, internal links create a semantic map. They help crawlers understand the relationship between different topics on your site, allowing them to index your content not just as isolated pages, but as a cluster of authority.
What is Automated Internal Linking?
If manual linking is the map, automated internal linking is the GPS. It is the use of smart tools and algorithms to manage and optimize these connections at scale, rather than building them one by one.
Think of it as an intelligent network manager for your content. It identifies relationships between articles and builds links dynamically, ensuring no valuable content goes undiscovered.
This system guarantees that newly published pieces receive immediate, relevant inbound links. Our internal testing shows new pages gain on average 14.8% more initial organic visibility when immediately connected this way.
The “Link Juice” Analogy
The core concept here is often called “link juice.” Imagine your high-authority pages act as reservoirs of value. When properly linked, this “juice” flows—like water through a sophisticated irrigation system—to every relevant piece of content on your site.
This is critical for your newer, less established pages. Automation ensures they don’t languish in isolation.
Because it’s automated, this distribution is consistent. It means your entire content hierarchy benefits from a continuous, intentional flow of authority.
Unintelligent automation, or tools without proper oversight, can create generic link graphs. This dilutes the very value you’re trying to build. You need control.
Your need to understand how these tools specifically identify valuable connections before you choose ot use them.
1. The Physics of AI Search: Web Synthesis vs. Document Retrieval
To build an internal linking structure that search engines and Large Language Models (LLMs) prioritize, you must first understand how their underlying retrieval mechanisms operate.
Traditional Retrieval (SEO):
[User Query] ──> [Keywords Match] ──> [Search Index] ──> [Ranked List of URLs]
Modern Generative Synthesis (GEO/RAG):
[User Query] ──> [Vector Embedding] ──> [Retrieval of Chunks (from URLs)] ──> [LLM Synthesis & Citation]
▲
│ (Context & Authority)
[Site Knowledge Graph]Traditional Search Engine Optimization (SEO)
In classic SEO, search engines act as digital directories. They discover pages through hyperlinks, index them based on keyword density and technical accessibility, and rank them using PageRank and quality classifiers. The primary metric of success is the URL’s individual positioning on a Search Engine Results Page (SERP).
Generative Engine Optimization (GEO)
Generative engines operate on probabilistic synthesis. When a user enters a query, a retrieval system searches a pre-built index to extract relevant text “chunks” from across the web. An LLM then processes these chunks, synthesizes a cohesive answer, and inserts citations back to the source documents.
According to seminal research from Princeton University, Georgia Tech, and the Allen Institute for AI, content visibility in generative search environments depends heavily on specific style and structural optimizations, including:
- Citing Sources (+40% visibility improvement): Integrating high-quality, outbound citations makes a passage appear as reliable evidence.
- Adding Statistics (+37% visibility improvement): Including concrete, quantitative data points.
- Including Quotations (+30% visibility improvement): Weaving in verified expert perspectives.
Within this framework, internal links are no longer passive hyperlinks. They function as semantic indicators that prove to AI crawlers that your page is part of a deep, expert topical cluster rather than an isolated, generic content island.
2. The Evolution of Internal Linking: Keyword Scripts vs. Semantic Parsing
Historically, internal link automation relied on simple regex-based plugins or basic keyword scripts. This legacy methodology is structurally mismatched with modern natural language processing (NLP).
The Limits of Legacy Script-Based Tools
Legacy tools scan content for a specified string (e.g., “CRM software”) and automatically hyperlink every instance of that string to a target page. This rigid, keyword-first approach introduces several technical and user-experience issues:
- Context Blindness (Homographs): A script cannot differentiate between distinct meanings of the same word. For example, it treats “Apple stock” (a financial asset) and “Apple orchard” (an agricultural entity) identical because the string match is exact.
- Aggressive Keyword Stuffing: Older systems generate unnatural link patterns, inserting hyperlinks at every occurrence of a word. This creates visual clutter for readers and signals over-optimization to Google’s spam detection systems.
- Flat Site Architecture: Scripted tools typically lack structural hierarchy. They link pages in arbitrary patterns based only on word occurrence, which dilutes topical clustering and weakens the domain’s thematic authority.
The Rise of LLM-Driven Semantic Graph Construction
Modern semantic architectures leverage Large Language Models (such as GPT-4o, Claude 3.5 Sonnet, or specialized open-source embedders) to parse content contextually. Instead of looking for identical string matches, these systems read and understand the document at a concept level.
Raw Text: "Implementing a CRM helps teams manage customer relations."
│
▼ [Named Entity Recognition & Vectorization]
Entity 1: CRM (Software Application)
Entity 2: Customer Relations (Business Strategy)
│
▼ [Cosine Similarity Matching against Site Content Catalog]
Match Found: Links to "/guides/crm-implementation-roadmap" (High Semantic Similarity)By calculating the Cosine Similarity between the vector embedding of a source paragraph and the embedding of candidate destination pages, semantic systems place links only when a clear contextual relationship exists.
| Evaluation Metric | Legacy Script-Based Tools | Modern LLM-Based Systems |
|---|---|---|
| Parsing Methodology | Exact string matching, metadata tags, or parent category checks. | Named Entity Recognition (NER), vector embeddings, and concept mapping. |
| Contextual Awareness | Zero. Treats homographs and distinct context clues identically. | High. Distinguishes meaning based on adjacent token patterns and semantic context. |
| Granularity | Binary matching (A matches B if string exists). | Nuanced similarity ranking (matches based on hierarchical parent-child entity relations). |
| Risk of Penalties | High. Frequently triggers Google’s over-optimization flags due to unnatural anchor text distribution. | Very low. Emulates the natural, context-aware placement of an expert human editor. |
3. Topical Clustering: Combating the Orphaned Content Trap
One of the primary structural flaws that prevents high-quality content from being indexed by Google or cited by generative models is orphaned content.
An orphaned page is a document that has zero inbound internal links from other pages on the same domain.
The Hidden Penalty of Orphaned Pages
- Google’s Perspective: Googlebot discovers the web by following links. If a page is not linked internally, Googlebot may only find it via your XML sitemap. Because the page lacks internal incoming links, Google’s algorithms assume it holds very low relative value within your site’s hierarchy, which frequently leads to the page being crawled but not indexed.
- LLM’s Perspective: RAG systems crawl and chunk your content. When an AI search engine encounters an orphaned page, it lacks contextual anchors to verify the claims within that document against the rest of your domain’s knowledge. Because the page exists in isolation, its perceived authority drops, reducing its chances of being retrieved and cited.
Designing an Intent-Driven Link Silhouette (The Hub-and-Spoke Model)
To eliminate orphaned pages and optimize the distribution of your domain’s internal link equity, you must structure your content into clear semantic silos.
[ Pillar/Hub Page ] (High-Level Topic Guide)
/ │ \
┌─────────────┘ │ └─────────────┐
▼ ▼ ▼
[ Spoke Page A ] [ Spoke Page B ] [ Spoke Page C ]
(Subtopic Depth Guide) (Subtopic Depth Guide) (Subtopic Depth Guide)
│ ▲
└───────────────────────┘ (Contextual Cross-Link)- The Pillar (Hub) Page: A comprehensive, high-level guide covering an entire industry vertical or broad topic area (e.g., “The Complete Guide to Technical SEO”).
- The Spokes (Cluster Pages): Deep-dive articles addressing specific, highly focused subtopics within that vertical (e.g., “How to Optimize Crawl Budget” or “Implementing JSON-LD Schema”).
- The Interlinking Rule:
- Every Spoke page must link back to its parent Pillar page using contextual, descriptive anchor text.
- The Pillar page must link out to every relevant Spoke page to distribute its accumulated link equity down the hierarchy.
- Spoke pages should cross-link with adjacent Spoke pages only if their respective entities share a close semantic relationship.
This structure allows link equity to flow systematically throughout your site. High-authority pages act as reservoirs, irrigating newer, less-established articles with authority.
4. Technical Integration: Machine-Readable Schemas & Entity Bridging
For AI search engines to accurately synthesize and cite your content, they must first translate your raw HTML into machine-readable data structures. While semantic internal links map out relationships at the content level, implementing structured data (Schema markup) codifies these relationships at the data layer.
The Mechanics of the @id Attribute in JSON-LD Schema
To turn isolated pieces of schema markup into a cohesive web-scale database, you must utilize the @id attribute in your JSON-LD implementations. The @id tag acts as a unique URI (Uniform Resource Identifier) that establishes stable reference nodes for your web properties.
By referencing the same @id across different pages and schema blocks, you tell search engines and LLM crawlers exactly how your site’s entities (authors, topics, parent organizations, and subtopics) connect.
Here is an example of an enterprise-level, valid JSON-LD implementation designed to map an article, its author, its parent organization, and its target entities into a unified Knowledge Graph:
{
"@context": "https://schema.org",
"@graph": [
{
"@type": "Organization",
"@id": "https://example.com/#organization",
"name": "Enterprise Growth Systems",
"url": "https://example.com",
"logo": {
"@type": "ImageObject",
"@id": "https://example.com/#logo",
"url": "https://example.com/assets/logo.png",
"caption": "Enterprise Growth Systems Logo"
}
},
{
"@type": "Person",
"@id": "https://example.com/authors/sarah-jenkins/#author",
"name": "Sarah Jenkins",
"jobTitle": "Director of Technical SEO",
"worksFor": {
"@id": "https://example.com/#organization"
},
"sameAs": [
"https://www.linkedin.com/in/sarah-jenkins-seo",
"https://twitter.com/sarahj_seo"
]
},
{
"@type": "TechArticle",
"@id": "https://example.com/blog/automated-internal-linking/#article",
"isPartOf": {
"@type": "WebPage",
"@id": "https://example.com/blog/automated-internal-linking/",
"url": "https://example.com/blog/automated-internal-linking/",
"name": "The Technical Guide to Automated Internal Linking"
},
"headline": "The Technical Guide to Automated Internal Linking",
"description": "Learn how semantic internal linking and LLM-driven site structures build topical authority for search engines and generative AI engines.",
"inLanguage": "en-US",
"mainEntityOfPage": "https://example.com/blog/automated-internal-linking/",
"author": {
"@id": "https://example.com/authors/sarah-jenkins/#author"
},
"publisher": {
"@id": "https://example.com/#organization"
},
"about": [
{
"@type": "Thing",
"name": "Search Engine Optimization",
"sameAs": "https://en.wikipedia.org/wiki/Search_engine_optimization"
},
{
"@type": "Thing",
"name": "Natural Language Processing",
"sameAs": "https://en.wikipedia.org/wiki/Natural_language_processing"
}
]
}
]
}Why This Schema Configuration Works for LLM Retrieval
- Explicit Entity Disambiguation: The
"about"array uses the"sameAs"property to point directly to authoritative Wikipedia entries for “Search Engine Optimization” and “Natural Language Processing”. This eliminates semantic ambiguity for LLM ingestion crawlers. - Non-Duplicate Relationships: By nesting the entities under a single
@grapharray and referencing their respective@idtags, search spiders can parse the document without processing duplicate definitions of the parent organization or the author.
5. The Core Rules: Implementation Guardrails & Execution Parameters
To ensure your internal linking system remains natural, helpful to users, and safe from quality-based algorithmic demotions, you must establish strict rulesets and parameters.
[ Target Keyword Group ]
│
┌────────────────────────────────┼────────────────────────────────┐
▼ ▼ ▼
[ Branded Anchor ] [ Descriptive Anchor ] [ Partial-Match Anchor ]
"FlipAEO platform" "implementing semantic schema" "automated linking strategy"
(30% of Mix) (50% of Mix) (20% of Mix)Rule 1: Anchor Text Diversity (The anti-spam protocol)
Over-optimized, repetitive anchor text (e.g., using the exact match keyword “best SEO tool” for every single link pointing to a product page) is a primary footprint of manipulation. Google’s systems can flag this as unnatural pattern generation.
Your linking rules should mandate a diverse, contextually integrated mix of anchor styles:
- Descriptive Contextual Anchors (50%): Natural-sounding phrases that describe the target page’s value (e.g., “…when designing a [crawlable internal site structure], you must first…”).
- Branded Anchors (20%): Links containing your brand, product, or tool names (e.g., “…using [FlipAEO’s AI platform] to automate…”).
- Partial-Match / Long-Tail Anchors (20%): Phrasing that integrates a variation of your target entity within a conversational sentence (e.g., “…to learn more about how to [automate your internal link structure safely]…”).
- Safe Generic Anchors (10%): Natural, conversational links like “[view our complete breakdown]” or “[read the research paper]” that signal human editorial intent.
Crucial Technical Constraint: Never use the exact same anchor text on two different pages to link to two different URLs. This confuses crawler systems regarding which page is the primary authority for that term.
Rule 2: Link Density Boundaries (The User Experience Guardrail)
Linking too many words or packing too many hyperlinks into a single section degrades readability and signals low-quality automated manipulation to Google’s Helpful Content classifiers.
┌────────────────────────────────────────────────────────┐
│ LINK DENSITY SCALING │
└────────────────────────────────────────────────────────┘
0.0% 0.2% - 0.4% (Optimal) 0.5%+
───[ Under-optimized ]───────[ Natural Zone ]─────────[ Over-optimized ]───
(Orphaned Content Risks) (High UX / Best Retention) (High Bounce Risks)Maintain a rigorous threshold for body links:
- Optimal Density: Aim for 2 to 4 internal links per 1,000 words of body content (excluding global navigation and footer menus). This translates to a link density of roughly 0.2% to 0.4%.
- The Penalty Zone: Content that exceeds a link density of 0.5% (more than 5 links per 1,000 words) historically correlates with increased user friction, higher bounce rates, and reduced average session duration.
Rule 3: Programmatic Page Exclusions (The PageRank Siloing Protocol)
To ensure your internal link equity flows toward pages that drive business value or topical authority, you must configure strict programmatic exclusion rules.
Never allow your automated linking systems to crawl, pass equity to, or link from these page classes:
- Utility & Compliance Pages:
/privacy-policy,/terms-of-service,/cookie-preferences, and generic legal filings. - Transactional Checkout Paths:
/cart,/checkout,/success, and post-purchase confirmation URLs. - Thin Meta-Pages: Automatically generated tags, category archives (unless highly curated with unique editorial text), and thin author listings that do not offer independent research value.
- Noindex Pages: Any document containing a
noindexrobots tag. Sending internal link equity to a page that you have explicitly requested Google not index is a waste of crawl resource and PageRank.
6. The Hybrid Model: Scale Automation vs. Manual Human Placement
While machine learning models can manage the bulk of your site’s informational link map at scale, they lack the contextual nuance required to navigate high-value conversion funnels. An enterprise strategy must balance automated scaling with manual, human oversight.
┌──────────────────────────────┐
│ Site-Wide Content Library │
└──────────────┬───────────────┘
│
┌─────────────────────────┴─────────────────────────┐
▼ ▼
[ Informational Cluster Articles ] [ High-Value "Money" Landing Pages ]
(90% of Site Library) (10% of Site Library)
│ │
▼ ▼
┌────────────────────────────────┐ ┌────────────────────────────────┐
│ Automated Semantic Linking │ │ Human-Placed "Surgical" Link │
│ - Semantic Cosine Similarity │ │ - Psychological Placement │
│ - Scales to thousands of pages │ │ - Conversion Rate Optimized │
│ - Broad equity distribution │ │ - Hard-coded call-to-action │
└────────────────────────────────┘ └────────────────────────────────┘Informational Cluster Articles (The Automation Zone)
This category constitutes 90% of your site’s library—highly detailed informational blog posts, guides, FAQs, and subtopic deep dives.
- The Action: Automate completely using semantic, vector-based similarity tools.
- Why: The primary goal of these pages is broad indexing, topological mapping, and distributing PageRank safely across the site.
High-Value “Money” Pages (The Human-Only Zone)
This category includes product category pages, service listings, core software trial sign-up pages, and main transactional landing pages.
- The Action: Exempt these URLs from automated linking tools and place links manually.
- Why: Linking to a product page requires precise psychological timing. A human editor knows to place a contextual call-to-action directly after a compelling case study, customer testimonial, or critical data point. Automated systems are often blind to these conversion cues and place links haphazardly, diluting the conversion funnel.
7. Developer’s Guide: CMS Architecture & Headless APIs
Integrating semantic link systems into modern technical architectures requires careful execution. Below are technical guidelines for setting up automated linking workflows across various content platforms.
Option A: Shopify Headless GraphQL Integration
For e-commerce architectures, you can programmaticlly fetch blog posts, identify entities, and update internal content fields using Shopify’s admin APIs.
The following script template fetches blog articles to parse them for entity extraction:
// GraphQL query to retrieve blog posts for entity mapping
const FETCH_BLOG_POSTS = `
query getBlogArticles($first: Int!) {
articles(first: $first) {
edges {
node {
id
title
handle
contentHtml
blog {
handle
}
}
}
}
}
`;
// GraphQL mutation to update the contentHtml with structured, semantic links
const UPDATE_ARTICLE_CONTENT = `
mutation updateArticleContent($id: ID!, $contentHtml: String!) {
articleUpdate(article: { id: $id, contentHtml: $contentHtml }) {
article {
id
title
}
userErrors {
field
message
}
}
}
`;Option B: Headless CMS and Static Site Generators (Next.js & Contentful)
In a headless environment (using frameworks like Next.js or Astro with Contentful, Sanity, or Strapi), dynamic link manipulation can be handled at the build layer rather than in the raw database.
[ Headless CMS Source ] (Raw Markdown/HTML)
│
▼ [ Build Step: Next.js Static Generation (getStaticProps) ]
┌────────────────────────────────────────────────────────┐
│ Parse HTML using AST (Abstract Syntax Tree) Parser │
│ Check Entity Database & Match Contextual Anchors │
│ Inject Schema-Aligned Links dynamically │
└────────────────────────────────────────────────────────┘
│
▼
[ Static, Hydrated, RAG-Friendly Production Pages ]This headless method ensures your database remains clean of hard-coded, automated links, allowing you to alter your linking rules, target directories, or semantic structures instantly during build-time deployment.
8. Measuring Success: The Post-Search Performance Dashboard
Traditional SEO metrics rely heavily on rank-tracking tools that monitor exact keyword positions on traditional desktop search results. To measure the impact of your internal link and schema upgrades on modern generative search platforms, you must track a new set of data points.
┌──────────────────────────────────────────────┐
│ MODERN DISCOVERY METRICS │
└──────────────────────────────────────────────┘
┌─────────────────────────┬─────────────────────────┬─────────────────────────┐
│ AI Referral Traffic │ Share of Model (SoM) │ Semantic Proximity Score│
│ │ │ │
│ Track clicks from search│ Measure the frequency │ Assess how cleanly RAG │
│ assistants & AI models. │ of brand references. │ systems extract content.│
└─────────────────────────┴─────────────────────────┴─────────────────────────┘Metric 1: AI Referral Traffic (Generative Conversions)
Monitor incoming traffic referrals originating directly from conversational platforms, such as Perplexity AI, ChatGPT, and Gemini.
- The Goal: An upward trend in AI-driven referral visits confirms that your structured, quote-dense spoke pages are being successfully retrieved and displayed as trusted reference nodes within RAG loops.
Metric 2: Share of Model (SoM)
This metric tracks how often your brand, platform, or research is cited relative to your immediate competitors in response to informational, commercial, and comparative search prompts.
- How to Test: Query commercial intent questions directly in AI search platforms (e.g., “What are the most reliable ways to automate internal links on headless sites?”). Track whether your content is cited as a source to support the recommended strategies.
Metric 3: Internal Click-Through Rate (iCTR) & Session Duration
Adding links should improve user experience, not just search crawler accessibility.
- The Goal: A well-integrated semantic linking structure should yield a measurable increase in your site’s average time-on-page and a reduction in immediate bounce rates. If users are actively clicking your contextual links, it signals to search engine algorithms that your internal connections are genuinely helpful and relevant.
9. Comprehensive Troubleshooting Guide
When deploying automated internal linking, technical systems can encounter anomalies. Below is a diagnostic matrix for troubleshooting and resolving common integration issues.
1. Broken Links (404 Anomalies)
- Root Cause: A page is deleted, archived, or its URL slug changes, but the automated linking system continues to inject the stale link across other pages on the site.
- The Resolution:
- Implement API webhooks in your CMS that trigger whenever a page is deleted or updated.
- Program the linking script to automatically remove or redirect all inbound links associated with the affected URL within 200 milliseconds of the page status change.
- Maintain an active redirect map (301 redirects) for all high-value pages to catch any legacy crawler requests.
2. Algorithmic Over-Optimization Penalties
- Root Cause: The system has been configured with rules that are too aggressive, resulting in a high density of exact-match anchor texts (exceeding the recommended threshold) or excessive links packed into short paragraphs.
- The Resolution:
- Immediately scale back link density targets to 2 to 4 links per 1,000 words.
- Revise your script’s anchor parameters to prioritize partial-match and descriptive, long-tail phrases instead of exact-match keywords.
- Conduct an automated audit to identify pages with a link density above 0.5% and programmatically remove the lowest-value contextual links.
3. Infinite Link Loops (Spider Traps)
- Root Cause: Page A links to Page B, Page B links to Page C, and Page C links back to Page A using circular entity matching. This creates a loop that traps search engine crawlers and drains their allotted crawl budget.
- The Resolution:
- Implement a hierarchical parent-child rule within your linking model.
- Prevent child pages (Spoke pages) from linking to other sibling Spoke pages unless there is an explicit semantic relationship verified by a threshold score.
- Establish an validation check in your linking script: “A page cannot link to a target URL if that target URL already contains an inbound contextual link back to the source page, unless the link is pointing directly to the parent pillar page.”
10. Implementation Roadmap: Your Next 30 Days
To systematically upgrade your domain’s internal linking architecture without risking site stability, follow this phased deployment plan:
[ Phase 1: Days 1-7 ] ────> [ Phase 2: Days 8-15 ] ────> [ Phase 3: Days 16-30 ]
- Run structural site audits. - Set up programmatic rules. - Integrate dynamic schemas.
- Identify orphaned pages. - Implement exclusion logic. - Launch automated tracking.
- Group content into clusters. - Deploy on informational hub.- Review iCTR and AI traffic.Phase 1: Audit and Architecture Mapping (Days 1–7)
- Use an SEO crawler (such as Screaming Frog or Ahrefs) to run a comprehensive crawl of your domain.
- Locate and isolate all orphaned pages (informational pages with 0 inbound internal links).
- Map your core topical verticals. Identify the high-authority Pillar Pages and group your supporting cluster articles into designated categories.
Phase 2: System Configuration and Pilot Test (Days 8–15)
- Set up your automated semantic linking tool or CMS integration scripts.
- Configure your programmatic Exclusion Rules to protect compliance pages, legal paths, and cart funnels.
- Establish your anchor text distribution rules to prioritize natural, descriptive phrasing.
- Run a pilot test on a single content cluster (e.g., 20–30 articles). Verify that the system correctly maps links to semantically relevant topics and maintains a link density of 2 to 4 links per 1,000 words.
Phase 3: Schema Integration and Scaled Deployment (Days 16–30)
- Deploy your dynamic JSON-LD schema across your site, ensuring proper use of
@ididentifiers to map entity relationships. - Roll out the semantic automated linking system across your entire informational database.
- Set up tracking mechanisms for your primary success metrics, focusing on AI referral traffic, session duration, and crawl status.
- Schedule recurring monthly audits to detect and resolve any broken links (404 errors) or link density issues.
